As part of the Masset digital asset management platform, we sometimes need to run tasks that take a long time. For example, when someone uploads a video, we may need to resize it to a few different sizes or extract the audio from it.
Originally we used AWS Lamdba for this because it allowed dynamic scaling, but eventually we found that the hard 15 minute execution limit was causing us trouble. Instead of doing a bunch of tasks to work around the limit, we decided to create a simple ECS Task. The task simply checks SQS if there is work to be done.
Note: Yes, I’m aware of AWS MediaConvert and similar offerings. There are a number of reasons why we don’t use it that we won’t get into here (the least of which is that it’s just too dang expensive). Also, video processing is just one of our long-running task types. We have others (like data processing) that can’t just be offloaded to managed services.
Unfortunately, there isn’t a built-in way in AWS to trigger ECS tasks from SQS queues. You have to trigger a Lambda from SQS or get tricky with long running processes. After examining the baselines for our workload, we decided we’d just run a long-cost ECS task on Fargate Spot and have it continually polling SQS. It kept our architecture simple and our baseline was already steady but extremely low usage.
To handle spikes and save costs, we setup scale-out and scale-in policies based on CloudWatch alarms. The number of tasks scales out if the SQS dwell time increases too much and scales back in if the dwell time drops. Simple, clean, and easy enough to define in a few Terraform files.
The Scale-In Cycle
What our initial implementation didn’t account for was the unfortunate side effects of long-running processes combined with scale-in policies. There are a bunch of cooldowns for both scaling in and out, but for sake of simplicity, the general scaling flow looks like this.
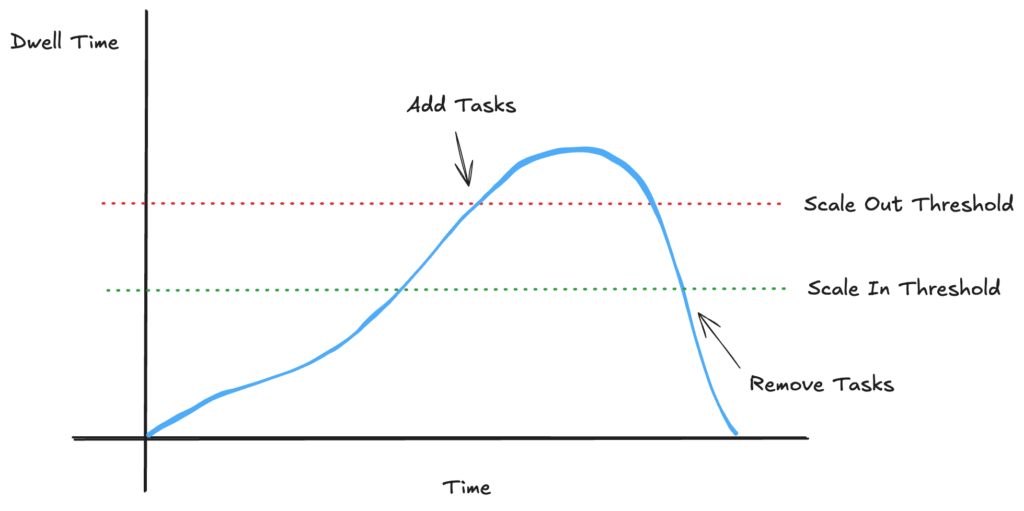
When we pass the scale-out threshold, we add tasks to consume the queue more quickly. When the pass the scale-in threshold, we remove tasks to save ourselves some dollar bucks (as my Bluey-mimicking kids have taken to saying). On the surface, this looks fine. What it doesn’t account for, though, is that the scale-in policy is going to terminate tasks when it thinks a task is no longer needed. The automated scaling doesn’t actually know if a task is done with it’s work or not.
Using dwell time as a scaling metric without some protections becomes a problem. SQS Dwell time includes messages that are currently in-flight. That can cause us to over-scale. Instead we can use the number of delayed messages. However, once we start taking things off the queue, the number of delayed messages starts dropping rapidly. Since the delayed messages has dropped, the scale-in policy triggers and tasks start getting harvested. Problem is… those tasks aren’t done with their work yet. In fact, they may have hours until they’re are complete. If you overlay the task lifecycles on top of our scale graph, the problem becomes easy to see.
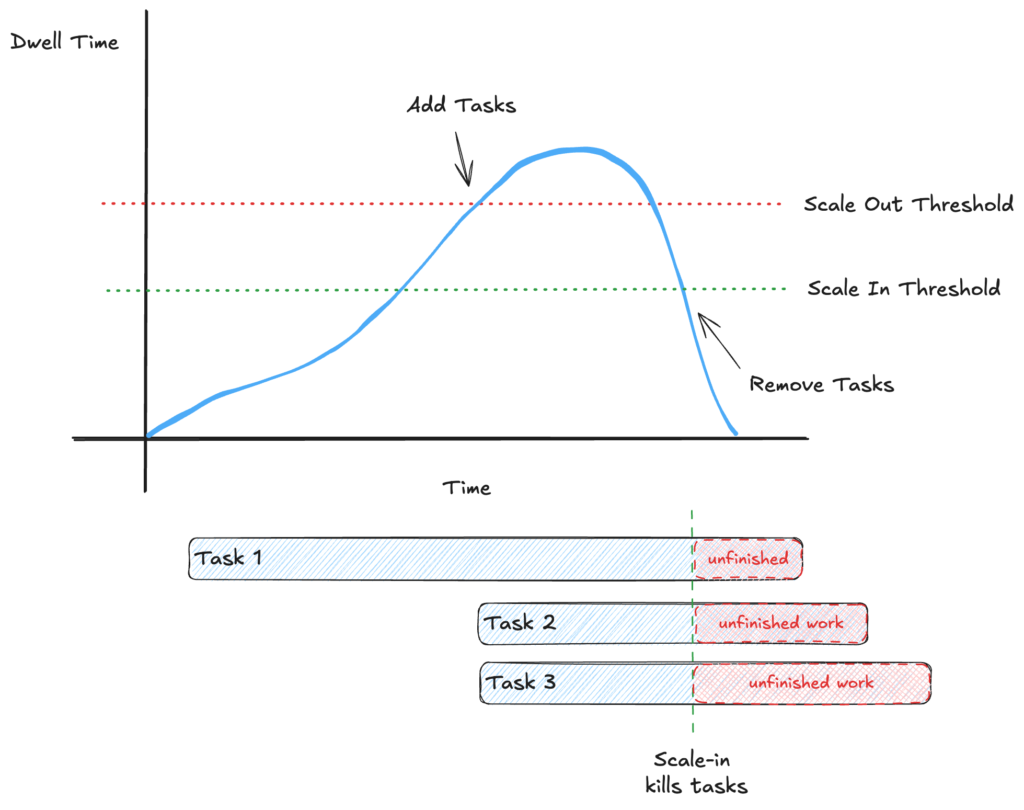
If we start killing tasks while they are still processing, then the work never completes. Since the work never completes, SQS messages never get acknowledged. Eventually, their visibility timeout expires and they become available again for listeners on the queue. If there aren’t any available listeners (we’ve scaled back in, remember?) then the number of delayed messages increases again. Scaling happens again. The message(s) are eventually consumed again by other tasks. Messages are in-flight again, so dwell time decreases again. So the scale-in policy triggers, and we kill the in-progress task again. Rinse and repeat.
If we follow this through to the worst case scenario, it’s possible that the scale-in policy will keep killing the oldest tasks so nothing ever finishes. We do get to help AWS’s bottom line by doing a lot of scale thrashing and paying for all of the task time even though it didn’t benefit us, so at least we are benefitting their shareholders. But it isn’t helping us. Not ideal.
We could switch our Cloudwatch alarms to monitor something other than SQS Dwell time, but I’ll save you the thought exercise and just let you know that no matter what metric you use, you could run into the same problem. Depending on the metric you choose, the prevalence could be greatly diminished, but the problem is likely still possible.
Thankfully the peeps at AWS are smart and clearly thought of this exact problem, because in Nov 2022, they announced ECS Task Scale-in protection.
Scale-in Protection
So what’s scale-in protection? Well, it’s exactly what we need.
Any given ECS task can be marked as “protected” from being killed based on scale-in policies. If you read through the documentation, it fits our use case perfectly… “You have a queue-processing asynchronous application such as a video transcoding job where some tasks need to run for hours even when cumulative service utilization is low.” Yep, sounds like a good fit!
Marking a task as protected can happen in two ways:
- It can be marked from a non-task global perspective. For example, I have a monitoring service periodically choose which tasks need to be protected.
- A task can mark itself as protected using the scale-in protection endpoint
Number 2 is what we need.
TaskProtectionManager
So we need a simple way of allowing a task to protect and unprotect itself when it starts a long running process. We also want it to be reusable in different parts of our application, so we’ll throw it in a quick Kotlin class TaskProtectionManager. Unfortunately, while there appears to be first class support in the AWS Java SDK for number 1, I was hard-pressed to find prebuilt support for #2. I’m not sure if it’s simply outside the scope of the SDK or just too new, but it unfortunately means we have to write a bit of code ourselves.
Adapting the example provided in the ecs-task-protection-examples repository, and augmenting it with knowledge directly from the docs, we come out with something looking like the code below. We use Jackson for JSON serialization and OkHttp for the REST calls since we already have them in our application, but you can use any libraries you want.
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.module.kotlin.registerKotlinModule
import okhttp3.MediaType.Companion.toMediaType
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody.Companion.toRequestBody
import org.apache.commons.logging.LogFactory
import org.springframework.stereotype.Service
class TaskProtectionManager {
private val LOG = LogFactory.getLog(TaskProtectionManager::class.java)
// ECS_AGENT_URI is injected when running in an ECS task
private val ecsEndpoint = System.getenv("ECS_AGENT_URI")
private val httpClient = OkHttpClient()
private val om = ObjectMapper().registerKotlinModule()
fun protectTask(expiresInMinutes: Int? = null) {
if (!runningInECSTask()) return
tryAndLog {
httpClient.newCall(buildRequest(true, expiresInMinutes)).execute()
}
}
fun unprotectTask() {
if (!runningInECSTask()) return
tryAndLog { httpClient.newCall(buildRequest(false)).execute() }
}
private fun buildRequest(
enabled: Boolean,
expiresInMinutes: Int? = null
): Request {
val expiryParams =
if (enabled && expiresInMinutes != null)
mapOf("ExpiresInMinutes" to expiresInMinutes)
else emptyMap()
val params = mapOf("ProtectionEnabled" to enabled) + expiryParams
return Request.Builder()
.url("${ecsEndpoint}/task-protection/v1/state")
.put(
om.writeValueAsString(params)
.toRequestBody("application/json; charset=utf-8".toMediaType())
).build()
}
/** Checks if we are running in ECS **/
private fun runningInECSTask() = !ecsEndpoint.isNullOrBlank()
/** Global catch-all and log **/
private inline fun tryAndLog(f: () -> Response): Response? {
try {
f().use {
if (it.code != 200) {
LOG.error(it.body?.string())
}
return it
}
} catch (e: Exception) {
LOG.error("failed to change task state", e)
return null
}
}
}Since we’re using Spring, we could get fancy and broadcast ApplicationEvents so that other components can listen to the state change, but this is sufficient for our basic needs.
Note: Unlike the linked example repository, we don’t maintain an internal state, although that would be relatively simple to add.
If your use case is more complex, you might want to use a counting semaphore inside the manager to ensure a task doesn’t unprotect itself if it’s still working on multiple tasks
Protecting When Processing
Now that we have the TaskProtectionManager built, we simply need to call it where ever we spawn our long running process.
@SqsListener
fun handleVideoResizeEvent(
event: VideoResizeRequestedEvent,
visibility: Visibility
){
// calculate the delay based on the duration of the video.
// based on measurements, we calculate it will safely complete
// within 2x the length of the video
val candidateVisibilityTimeout =
event.durationMs?.let { it / 1000 * 2 }?.toInt()
?: DEFAULT_TIMEOUT
val clampedTimeout = min(candidateVisibilityTimeout, MAX_TIMEOUT)
visibility.changeTo(clampedTimeout)
try {
// mark the task as protected while we are processing.
TaskProtectionManager().protectTask(clampedTimeout / 60)
// do the resizing
videoResizeService.resize(event.s3Path)
} finally {
// make sure we always unprotect
// mark the task as protected while we are processing.
TaskProtectionManager().unprotectTask()
}
}In our case, we are responded to an SQS event in Spring using @SQSListener.
By surrounding our processing logic with the protection calls, we’ve ensured that we’ll be given the necessary time to complete our long-running job.
As a bonus, I’ve included the logic we use to delay the visibility of the message based on a calculation using the length of the video. This allows a timeout for each SQS message to be dynamic based on how long we anticipate it will take to process. In reality, this calculation includes an average processing time per second of video, based on # of available CPUs, duration of the video, and the video dimensions. But for the example here, we assume things will safely finish within the length of the video*2. You’ll want to remove that logic or customize it to your purposes.
Update your task role
Now that the code is in place, don’t forget that you’ll need to make sure that your task execution role has permissions to change the protection state. At a minimum you’ll need to assign a policy that grants ecs:UpdateTaskProtection. If for some reason you want to check the state, you’ll need ecs:GetTaskProtection as well.
Conclusion
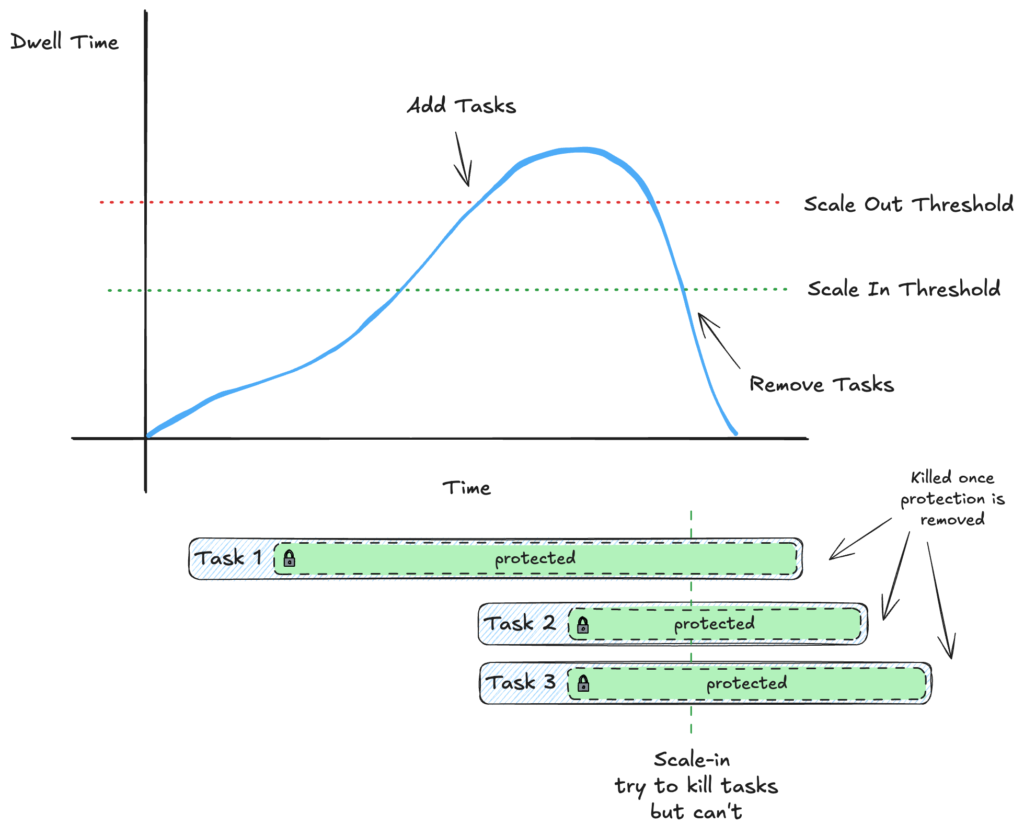
Now that we are using scale-in protection, we no longer have to worry about the infinite scaling cycle that we had before.
AWS can do what it needs to scale out our services and compensate for increased dwell time/load. When AWS determines our ECS service needs to scaled in, our tasks are allowed to finish since they are protected. Once protection is lifted by each task, it will terminate and the cluster will be right sized!
Next Steps
While what we have is already functional, there are a few things we could do to improve it further.
- Extension functions
- Since we’re in Kotlin, it’d be nice to add a few helper or extension functions. For example, something like
doProtected{} could be nice to eliminate the possibility of accidentally forgetting to unprotect tasks.
- Since we’re in Kotlin, it’d be nice to add a few helper or extension functions. For example, something like
- Temporarily pause new jobs
- While we are protected, AWS can’t shut down our task, which is exactly what we want. But if we have a big backfill on our queues, this task could endure for a really long time if we let it.
- We probably want to have a window of time between processing of jobs where AWS can inject itself to shut down the container if necessary. Depending on how we deploy, this might be necessary to ensure that old tasks don’t stick around forever when we deploy new task versions.