This is the first post in a two-part series on how Masset identified and removed downtime when deploying it’s React-based Single Page Application (SPA) frontend.
- In Part 1 (this article), we discuss the problem and identify a solution.
- In Part 2 (upcoming), we write the necessary Terraform code and deploy to production
TLDR: Container-based static sites suffer from downtime when using rolling deployments. We can use a CDN (Cloudfront in this case) to mitigate the issue and get some fringe benefits in addition.
Introduction
When we first got started on building Masset, our primary goal was simplicity. Simple to build and simple to deploy. We really wanted to emphasize a focus on customer problems, not burn innovation tokens.
To honor that simplicity, we went with what we already knew. Our frontend was built in React, and our backend in Spring Boot/Kotlin. We decided to keep it simple and deploy both in Docker containers. The backend was a simple health check and bundled JAR (yes we know that unpackage is more efficient, but we don’t need the small gains right now).
For the React frontend, we setup a multi-image container following the builder pattern and copied all built files into a static nginx image to be served. We configured a few quick health checks on the containers and deployed using ECS. And that worked great! Or so we thought…
A few weeks in, we got our first customer notification that the site wouldn’t load. “But I refreshed the page a few times and it resolved itself” the ticket said.
Welp, that is not an ideal experience for our customers. We decided to dig in and take a deeper look.
Investigation
After running deployments in our test environments, we were able to confirm the problem was related to release windows.
After failing to diagnose the problem using manual testing, We setup a simple bash script that curl’ed the site at an interval of 500 ms. Nothing showed up. We never saw anything other than a wonderful 200 success code. Odd.
So we went closer to the user experience. We wrote a quick Playwright script to actually drive the browser. And boom! Sure enough, during a release, there was between 15-20 seconds of time where the frontend would fail to load when in a browser. A small window of time, sure, but problematic when the app is continuously used.
What was going on? Shouldn’t our health checks ensure this isn’t happening?
The Problem
Well, it turns out the world is not a simple as we like to believe it is. We added network-request-recording to our Playwright script and quickly found the root cause. Our requests to index.html were successful (hence the successful curl’ing), but requests to our static JS and CSS files would periodically fail. When the JS files failed to load, the site didn’t load. Well, there’s the problem!
We use hashing on our static files so that we can do aggressive caching. Download it once and it’s always there. For the sake of simple explanation, let’s say that our hashing is simple version strings (oldHash and newHash). Sometimes main.[oldHash].js would return successfully, other times it would return a 404 error. Same for main.[newHash].js. Sometimes success, sometimes failure.
With this newfound information, we realized our mistake. I’m a visual learner, so diagraming out the flow made it easy to see for me.
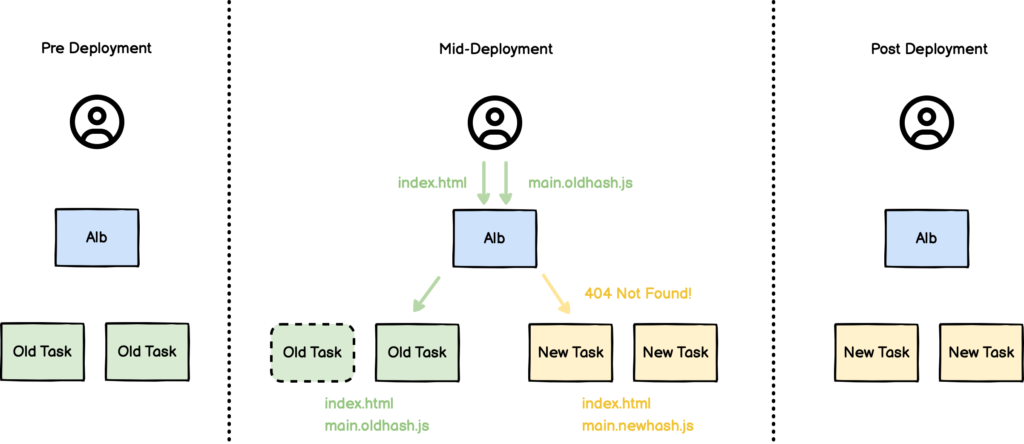
While we are in the process of a rolling deployment, we have 2 versions of the frontend containers running. The old version has an index.html that points to main.[oldHash].js and the new version has an index.html that points to main.[newHash].js. Although we are in the process of draining and stopping the old tasks, both are still valid targets for our load balancer for a short window of time. When requests hit the load balancer, they will be round-robin’ed to whichever container the ALB deems fit to respond. Sometimes they will hit the new, sometimes the old.
This doesn’t cause a problem when we’re requesting index.html; it actually doesn’t matter which index.html page we serve in the short overlapping window. The problem comes from the follow up requests. If we hit the old index.html, the subsequent request will be for main.[oldHash].js. If we get the new index.html, it’ll be for main.[newHash].js. Either way, we’re in trouble.
Our new containers have main.[newHash].js but not main.[oldHash].js. And our old containers have the inverse. The load balancer doesn’t know which file lives in which container. If it happens to send to the wrong once, we got a 404, and boom, page doesn’t load.
Note: We don’t use Kubernetes because we don’t need the additional flexibility offered above ECS. However, this same problem exists when deploying rolling updates to k8s services, or really any other rolling deployment behind a load balancer.
Possible Solutions
Originally, we wondered if we could just package the old static files into the new containers and be done with it. It’d be a simple tweak to our build pipeline and we’d be done. But after some debate, we realized that would only solve half the problem. Having the old files in the new containers means the hit rate would increase, but would still miss if main.[newHash].js was routed to an old container. We needed to handle both failure cases, requests for old files being routed to new containers and requests for new files getting routed to old containers. In short, we need to have a foolproof way to ensure requests could always get to the correct files.
Not surprisingly, we weren’t the only ones to run into this problem. It took some digging, but we eventually found some Stack Overflow and Reddit posts that talked about the same problem. For something that felt like such a common problem, it didn’t really feel like there was a best practice solution. Recommended solutions were all over the map (one the reasons we decided to write this post)!
At the conclusion of our research, we determined that there were a few candidate solutions that might work for us.
- Sticky sessions
- HTTP 2 multiplexing
- Blue/Green deployments
- CDN
Sticky Sessions
Sticky sessions feels like an obvious answer. If a client requests the new index.html, attach all future requests to that same container. That way it is always getting the coordinated files. Simple in theory, difficult in reality.
For lack of a better explanation, implementing sticky sessions just felt… gross. There were too many ways for it to go wrong. What if a user wasn’t authenticated? We’d have to create a sticky session based on an anonymous token of some sort. Could we be certain that sticky sessions would properly pass through our load balancers? What if we introduced another jump for a WAF? Would it still work?
The solution just felt too disconnected from the problem. Sure, sticky sessions, might solve the problem, but in a distributed employee world, how is the infrastructure guy supposed to know that sticky sessions are there to solve a deployment issue? It just didn’t feel right.
HTTP 2 Multiplexing
HTTP 2 is an interesting solution to this problem. Because of its ability to multiplex, it can have a single connection to a server and download multiple files. In theory, this is essentially a poor-man’s sticky session for assets coming over the public internet.
However, it suffers the same problems as sticky sessions. The solution felt too disconnected from the problem. All it would take was a single employee to not understand why all connections have to be HTTP 2 and the problem is re-introduced.
Blue/Green deployments
The idea of blue/green deployments is not new. It’s been a common practice in the DevOps world for a while now. The basic idea is that you spin up a duplicate infrastructure and then cut over all at once once your status checks pass. Instead of doing a rolling deploy, we’d bring up all the new frontend containers, and shift load balancer traffic all at once. Compared to rolling updates, it requires twice the provisioned resources, but has the added benefit of simpler cut-overs.
As with all solutions, blue/green deployments have some pros and cons. Since there is duplicated infrastructure, it is very easy and quick to rollback if needed. Technically you can do interesting things like canary deployments and partial load balancing as well, but that would actually violate our “all-or-nothing” requirement for our frontend deployments.
Unfortunately, we can’t really capture a lot of the pros of blue/green deployments because of our hard constraints (at least for our frontend). If we implement partial- or percentage-based routing, we’ve reintroduced the same problem. And going back to the ownership problem, the person responsible for deployment process is not likely to know why we needed blue/green deployments other than through tribal knowledge. It’s way to easy for someone to trigger a rolling deploy and have downtime. That’s a failure of process and design. Someone shouldn’t be able to create such a problem accidentally.
CDN
Which leaves our final solution, a Content Delivery Network (or CDN for short). CDNs can best be described as a distributed network of proxy servers that use heavy caching to accelerate request. Normally they are geographically diverse, so that loading a site in Asia is just as fast as loading it in Minnesota. But how does that help us? We aren’t really concerned about making JS load times faster… at least right now. Heck we just want it to load at all! 😂
Well, in our case, we are more keen on using the delivery part of a CDN. In order to distribute content on a CDN, you need to make it available for the CDN to cache it. Behind the scenes, you point a CDN to some sort of backing storage. This can technically be anything; a web server, object storage (like S3 or R2), or even something like IPFS.
In our case, the backing storage is really where we get our benefit; the CDN is just a fancy web server in front of our storage. That storage is where we can push our static assets. The key is that we need to push the newest version of our static assets before any requests receive the new index.html in the new containers. We also won’t remove old versions of static assets from the backing storage, at least not immediately. That means that if a request hits the CDN for static assets, it will be able to proxy to get both files.
If we didn’t want to rely on a CDN, it is feasible that we could just run another web server that pulls static files directly off disk and route our ALB to that. Our build process could publish to that server disk, but after dealing with redundancy, routing, backups, security, etc, it’s probably simpler to just use a CDN.
Our Solution
After debating all the options, we decided to move forward with a CDN as our first attempt. After evaluating all of the options, we felt it was the simplest option that would remain relatively foolproof over time. It felt like the most likely solution, at our stage of company, such that it the problem wouldn’t randomly reappear.
Note: Full transparency, the CDN decision was also influenced by the fact that it was already in our backlog. We knew as we continued to add more and more users overseas we would eventually need the distributed caching benefits of a CDN anyways. Instead of being a net new problem to solve, we thought we could kill two birds with one stone. The evaluation criteria for your company may be different.
As mentioned previously there are a number of approaches to take when implementing a CDN. These approaches led to some continued investigation and honing of our exact approach.
If you’re considering this for yourself, here are some general questions you’ll want to ask yourself.
Which vendor should I use for this?
Unsurprisingly, there are a number of vendors that will do this for you. The big three cloud providers each have their own versions. On top of that, there are other companies like Cloudflare, Akamai, and Fastly that all have speciality versions that excel in specific scenarios. For us maintaining simplicity was the biggest factor, so that meant no new vendors. We are already an AWS shop, so AWS Cloudfront it is.
How should we back the CDN?
In some ways, this question varies based on who you choose for your vendor. Most CDNs have the ability to back them with different types of “origins”; they generally all support some level of backing by object storage (S3/R2/etc) or proxying to a web server, load balancer, domain, or other public internet location (the vernacular here varies somewhat vendor to vendor). In our case, it was simplest to back by an object storage.
What should be “behind” the CDN?
Depending on the vendor you use and your traffic patterns CDNs can get expensive. Some vendors charge per request, some charge egress fees, and some charge based on hits/misses to the cache. All of that can add up. At Masset, we determined long ago that margins matter. We don’t buy solutions that require us to pass the buck to our customers.
One way that you can mitigate some of the cost is to limit what you put behind the CDN. In most web applications, you will have static files and dynamic API requests. Those dynamic API requests might be dynamically generated HTML pages, or they might be JSON served over REST.
There’s a fair argument to say that all dynamic content should be served in front of the CDN, since it can’t be cached anyway. In that scenario, you would setup CORS on your CDN and your HTML page would point to the CDN only for your static assets. All the API requests would go directly to your load balancer.
The opposite approach is to simply say that everything goes behind the CDN. You end up paying for requests that aren’t reused, and you won’t get the benefits of caching on dynamic content. On paper, it seems like a list of cons without any real benefit. But there is one significant benefit: fronting API requests with a CDN essentially operates like a regional API gateway. What do we mean by that? Well, imagine a customer is using the site in Asia and you’re hosted in Virginia. Their request will enter the cloud network in Asia, which generally leads to quicker response times overall than routing it all the way to Virginia. For things that have round trip latency like HTTPS termination, it can make a difference. It also provides the opportunity to inject dynamic routing to different geographical regions when necessary. I highly encourage not going multi-region until absolute necessary, but it’s nice to know that we can when needed.
For us, it was a toss up and we waffled back and forth. In the end, we decided to front everything with the CDN. We have just enough overseas users that the regional gateway benefits made sense. That said, we are actively monitoring the cost associated with this approach. If it gets out of hand, there’s a good chance we’ll switch to only fronting static assets.
How are you going to handle caching?
Finally, you need to decide how you’re going to handle caching. There are two levels of caching in a CDN.
- Browser -> CDN
- CDN -> Origin
When deciding your caching strategies, it’s important to consider both. Browser -> CDN cache will determine how frequently the browser requests new versions. Our recommendation here is to set it as long as reasonably allowed. As called out previously, we use hash-based approach for versioning our static files. As such, we set our caching to 1 year, essentially a forever-cache. Once a user has downloaded the static assets, they have them forever.
Note: In case this isn’t clear from context, I figured we’d make it explicit. We don’t consider index.html a “static” file, despite being generated in the frontend build process. It is always served from the active frontend container and is never cached. This ensures that new page loads always request the latest assets so we don’t have old clients sitting around forever. The index.html is small enough (<1kb gzipped), that this is not problematic.
The CDN -> Origin cache dictates how frequently the CDN will invalidate it’s own cache and attempt to get a new version. For hash-based approaches, this remains fairly simple. We will never be updating the hashed assets, so a long cache time is great. If your assets do not use hashing, you’ll need to take this cache timing into consideration. Otherwise, if you overwrite your old main.js asset with a new one, the CDN won’t use it. You would need to either 1) wait for the CDN cache to expire, or 2) invalidate the CDN cache.
Conclusion
In this article, we’ve identified the problem with rolling container deployments for static frontends. We also identified and discussed 4 different solutions. In the end, we decided that using a CDN is likely the best scenario for the Masset implementation.
In part 2, we will use Terraform to build and deploy the necessary infrastructure and components for the Cloudfront CDN.